Classification Models - Random Forest
Description
A Random Forest is an ensemble learning method used for classification in machine learning. It constructs multiple decision trees during the training phase and combines their predictions to make a final prediction.

Each decision tree is constructed using a random subset of the training data and features. This randomization helps to reduce overfitting and makes Random Forests more robust. During prediction, each tree in the forest independently classifies the input, and the final prediction is determined by majority voting.
Random Forests have several advantages, including high accuracy, resistance to overfitting, and suitability for large datasets. They can handle both categorical and numerical features and are capable of computing feature importances.

Random Forests have various applications in areas such as healthcare, finance, and image recognition. They are widely used due to their flexibility, simplicity, and ability to handle high-dimensional data. Additionally, Random Forests can handle missing values and outliers without preprocessing. However, they might be slow for real-time predictions and can be difficult to interpret.
Overall, Random Forests are a powerful tool for classification tasks and have become a popular choice in the machine learning community.
History
Random Forest is an ensemble learning method that combines multiple decision trees to make predictions. It was introduced by Leo Breiman in 2001. Random Forests create each tree using a subset of data and random feature selection, reducing overfitting. This algorithm gained popularity due to its flexibility, accuracy, and ability to handle large datasets. By aggregating predictions from individual trees, Random Forests can classify data accurately and handle both categorical and numerical features efficiently. Today, it is widely used for both classification and regression tasks in various domains.Use Cases
- Fraud detection: Random Forest can be used to classify fraudulent transactions by analyzing various features such as transaction amount, location, and customer behavior.
- Medical diagnosis: It can help classify medical conditions like diseases or tumors based on patient data, medical history, and symptoms.
- Customer churn prediction: By analyzing customer behavior, demographics, and engagement metrics, Random Forest can predict whether a customer is likely to churn or cancel their subscription.
- Image recognition: Random Forest can be utilized to classify images into different categories such as objects, animals, or facial expressions.
- Spam email detection: By analyzing email content, metadata, and patterns, Random Forest can determine whether an email is spam or legitimate.
- Sentiment analysis: It can classify the sentiment of textual data, such as social media posts or customer reviews, into positive, negative, or neutral.
- Loan default prediction: Random Forest can predict the likelihood of a customer defaulting on a loan by analyzing their credit history, income, and other relevant factors.
- Recommendation systems: It can classify user preferences and behaviors to provide personalized recommendations, such as movies, products, or songs.
- Weather prediction: By analyzing historical weather data, geographic features, and atmospheric conditions, Random Forest can predict weather patterns and forecast future temperatures or precipitation.
- Medical image classification: Random Forest can help classify medical images, such as X-rays or MRI scans, to aid in diagnosing various conditions or diseases.
Pros
- High Accuracy: Random Forest models are known for their high accuracy in classification tasks. They produce reliable results by combining the predictions of multiple decision trees.
- Robust to Outliers: Random Forests are less sensitive to outliers compared to other classification models. The model's accuracy is not significantly impacted by extreme values in the dataset.
- Implicit Feature Selection: Random Forests perform implicit feature selection, meaning they automatically assess the importance of each feature in the classification task. This helps identify the most relevant features for prediction.
- Handles Large Datasets: Random Forests can efficiently handle large datasets with high dimensionality. They are capable of training on a large number of features and instances without compromising performance.
- Reduces Overfitting: Random Forests are designed to reduce overfitting by aggregating multiple decision trees. They mitigate the risk of memorizing the training data and generalize well to unseen data.
Cons
- High computational complexity: Random Forests require more computational resources and time for training and making predictions compared to simpler models due to the ensemble nature and construction of numerous decision trees.
- Overfitting potential: Although Random Forests generally mitigate overfitting, it is still possible to overfit the model if the number of trees in the forest is too large or if the trees are allowed to grow to their full depth.
- Lack of interpretability: Random Forests provide limited interpretability as the prediction outcome is based on an aggregation of multiple decision trees, making it difficult to determine the specific feature interactions and their influence on the predictions.
- Memory consumption: Random Forests require a considerable amount of memory to store the ensemble of decision trees, especially when dealing with large datasets or when ensemble size is large.
- Model performance variation: The performance of Random Forests can be sensitive to the choice of hyperparameters and the specific random seed used during training, leading to potential variation in model performance across different runs.
Hyper parameters
- n_estimators: The number of decision trees in the random forest.
- max_depth: The maximum depth of each decision tree.
- min_samples_split: The minimum number of samples required to split an internal node.
- min_samples_leaf: The minimum number of samples required to be at a leaf node.
- max_features: The maximum number of features to consider when looking for the best split.
- bootstrap: Whether to use bootstrap samples when building trees.
- class_weight: Weights associated with classes in the form of a dictionary.
Pitfalls
- Overfitting: Random Forest can overfit the training data if the trees are allowed to grow too deeply. It is necessary to tune parameters such as maximum tree depth, minimum samples per leaf, and maximum features to prevent overfitting.
- Computational complexity: Random Forest can be computationally expensive, especially when dealing with large datasets or a high number of trees in the forest. Training and predicting can take a significant amount of time and resources.
- Lack of interpretability: Although Random Forest provides accurate predictions, interpreting the results can be challenging. The ensemble nature of Random Forest makes it difficult to understand the contribution of individual features towards the final prediction.
- Imbalanced data: When dealing with imbalanced datasets, Random Forest may be biased towards the majority class. This can result in poor performance on the minority class. Techniques such as resampling or adjusting class weights may need to be applied to address this issue.
- Dependency on hyperparameters: Random Forest requires careful tuning of hyperparameters to achieve optimal performance. The choice of the number of trees, maximum depth, and other parameters can significantly impact the model's accuracy.
Algorithm behind the scenes
Sure! Random Forest is an ensemble method that combines multiple decision trees to make predictions. Each decision tree is constructed as follows: 1. Randomly select a subset of the training data. 2. Randomly select a subset of features. 3. Construct a decision tree using the selected data and features. 4. Repeat steps 1-3 to create multiple decision trees. To make a prediction, the Random Forest algorithm uses the majority vote of all decision trees in the ensemble. The class with the highest number of votes is selected as the final prediction. Now, let's go through the math details of Random Forest. 1. Random sampling: In each decision tree, the algorithm randomly selects a subset of the training data to build the tree. This is known as random sampling with replacement, or bootstrap sampling. The size of the subset is typically equal to the size of the original data, but some samples may be duplicated while others may be excluded. 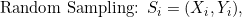 2. Random feature selection: At each node of the decision tree, the algorithm randomly selects a subset of features to consider for splitting. This helps to introduce variability and reduce the correlation among the trees. The number of features to select is typically the square root of the total number of features. 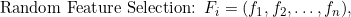 3. Constructing the decision tree: The decision tree is built recursively by partitioning the data based on the selected features. Each node in the tree represents a decision or a feature threshold. The splitting criteria, such as Gini impurity or information gain, are used to find the best feature and threshold that maximize the separation of classes. Once all decision trees are constructed, predictions can be made by aggregating the predictions of all trees through a majority voting scheme. Overall, the Random Forest algorithm combines the randomness of data sampling and feature selection with the robustness of decision trees to create a powerful ensemble model for classification tasks in machine learning. I hope this explanation helps!Python Libraries
Code
Sure! Here are some code samples using the Random Forest algorithm for machine learning classification models in popular Python libraries:
1. scikit-learn:
```python
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# Load the iris dataset
data = load_iris()
X = data.data
y = data.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Create a Random Forest classifier
clf = RandomForestClassifier(n_estimators=100)
# Train the model on the training set
clf.fit(X_train, y_train)
# Predict on the testing set
y_pred = clf.predict(X_test)
# Evaluate the model
accuracy = clf.score(X_test, y_test)
print("Accuracy:", accuracy)
```
2. XGBoost:
```python
import xgboost as xgb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# Load the iris dataset
data = load_iris()
X = data.data
y = data.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Create a Random Forest classifier with XGBoost
params = {'objective': 'multi:softmax', 'num_class': 3, 'n_estimators': 100}
clf = xgb.XGBClassifier(**params)
# Train the model on the training set
clf.fit(X_train, y_train)
# Predict on the testing set
y_pred = clf.predict(X_test)
# Evaluate the model
accuracy = clf.score(X_test, y_test)
print("Accuracy:", accuracy)
```
3. LightGBM:
```python
import lightgbm as lgb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# Load the iris dataset
data = load_iris()
X = data.data
y = data.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Create a Random Forest classifier with LightGBM
params = {'objective': 'multiclass', 'num_class': 3, 'num_iterations': 100}
clf = lgb.LGBMClassifier(**params)
# Train the model on the training set
clf.fit(X_train, y_train)
# Predict on the testing set
y_pred = clf.predict(X_test)
# Evaluate the model
accuracy = clf.score(X_test, y_test)
print("Accuracy:", accuracy)
```
These code samples demonstrate how to use the Random Forest algorithm for classification using scikit-learn, XGBoost, and LightGBM libraries in Python.